Hotline:
1800 2222
Tác giả: Lê Việt Ạnh Ngày đăng: Tháng 1 22, 2025
Mục Lục Bài Viết
Mã di truyền là tập hợp các quy tắc mà tế bào sống sử dụng để dịch thông tin được mã hóa trong vật liệu di truyền (chuỗi DNA hoặc mRNA). Trong quá trình này, ribosome đóng vai trò quan trọng khi thực hiện việc dịch mã. Ribosome liên kết các axit amin theo thứ tự được xác định bởi mRNA, thông qua việc sử dụng các phân tử tRNA để vận chuyển axit amin. Đặc biệt, ribosome đọc mRNA theo từng bộ ba nucleotide một lúc để xác định chính xác axit amin nào cần được thêm vào chuỗi protein.

Về cấu tạo, mã di truyền trong mỗi gen được hình thành từ bốn loại bazơ nucleotide cơ bản của DNA, bao gồm adenine (A), cytosine (C), guanine (G), và thymine (T). Trong RNA, thymine (T) được thay thế bằng uracil (U). Các nucleotide này kết hợp với nhau thành những bộ ba chữ cái, được gọi là “codon”, và mỗi codon này có nhiệm vụ xác định loại axit amin cụ thể cần được đặt tại từng vị trí trong chuỗi protein.
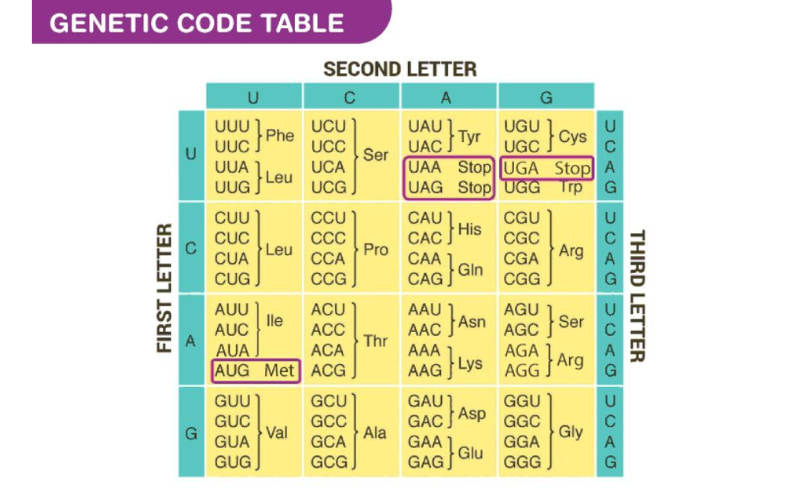
Bảng mã di truyền thể hiện toàn bộ mối quan hệ giữa axit amin và codon. Trong bảng mã di truyền, một axit amin có thể được mã hóa bởi nhiều codon khác nhau. Một ví dụ điển hình là axit amin leucine có thể được biểu thị bằng 6 codon khác nhau trong ngôn ngữ mRNA.
Codon được định nghĩa là một chuỗi ba nucleotide liên kết với nhau, tạo thành một đơn vị mã di truyền cơ bản trong phân tử DNA hoặc RNA.
Một đặc điểm quan trọng của mã di truyền là tính phổ quát của nó – hầu hết các sinh vật trên Trái đất đều sử dụng cùng một bộ mã di truyền để tổng hợp protein, chỉ có một số ít ngoại lệ.
Về bản chất, mã di truyền chính là quá trình chuyển đổi từ trình tự nucleotide của các bazơ trên DNA thành trình tự các axit amin tương ứng để tổng hợp nên protein cần thiết.
Nghiên cứu về mã di truyền là một hành trình dài và đầy thách thức trong lĩnh vực sinh học và di truyền học, kéo dài suốt các thế kỷ 19, 20 và 21, mang đến cả những hứa hẹn lẫn những nguy cơ tiềm ẩn. Một bước ngoặt quan trọng đã diễn ra vào năm 1944, khi Oswald Avery chứng minh được DNA chính là vật mang thông tin di truyền, chấm dứt hơn 80 năm suy đoán của giới học thuật. Từ đó, DNA đã trở thành yếu tố then chốt trong kỷ nguyên vàng của sinh học phân tử, góp phần thúc đẩy sự phát triển và cách mạng hóa các lĩnh vực khoa học liên quan đến di truyền và gen.
Nghiên cứu để tìm hiểu bản chất của mã di truyền không chỉ giúp con người có cái nhìn sâu sắc hơn về tính phức tạp và đa dạng của nó, mà còn mở ra nhiều cơ hội mới trong việc tìm hiểu và phát triển các phương pháp điều trị cho các bệnh di truyền.

Mã di truyền được tổ chức theo dạng mã bộ ba, hay còn được gọi là codon, trong đó mỗi codon là một nhóm các nucleotide có chức năng xác định một axit amin cụ thể. Các nghiên cứu khoa học đã cung cấp những bằng chứng xác thực chứng minh rằng mỗi trình tự gồm ba nucleotide sẽ mã hóa cho một axit amin trong chuỗi protein, từ đó xác nhận tính chất của mã bộ ba.
Có bốn loại nucleotide cơ bản là A, G, C và U được sử dụng để tạo nên các codon ba nucleotide. Tổng cộng có 64 codon khác nhau, bao gồm cả các codon có nghĩa (quy định các axit amin) và codon vô nghĩa (chứa thông tin dừng tổng hợp protein). Với việc có 64 codon nhưng chỉ mã hóa cho 20 axit amin, điều này dẫn đến hiện tượng một axit amin có thể được mã hóa bởi nhiều codon khác nhau.
Tính thoái hóa là một đặc điểm quan trọng trong sinh học di truyền, thể hiện tính linh hoạt của mã di truyền khi nhiều codon khác nhau có thể cùng mã hóa cho một axit amin trong quá trình tổng hợp protein. Điều đặc biệt là sự đa dạng này của các codon không gây ảnh hưởng đến cấu trúc hay chức năng của protein được tổng hợp cuối cùng.
Mã di truyền có hai đặc tính nổi bật: tính đặc hiệu và tính phổ biến. Về tính đặc hiệu, mỗi codon cụ thể chỉ có khả năng mã hóa cho một loại axit amin nhất định. Về tính phổ biến, hầu hết các sinh vật trên Trái đất đều sử dụng chung một bộ mã di truyền, mặc dù có một số ít trường hợp ngoại lệ.
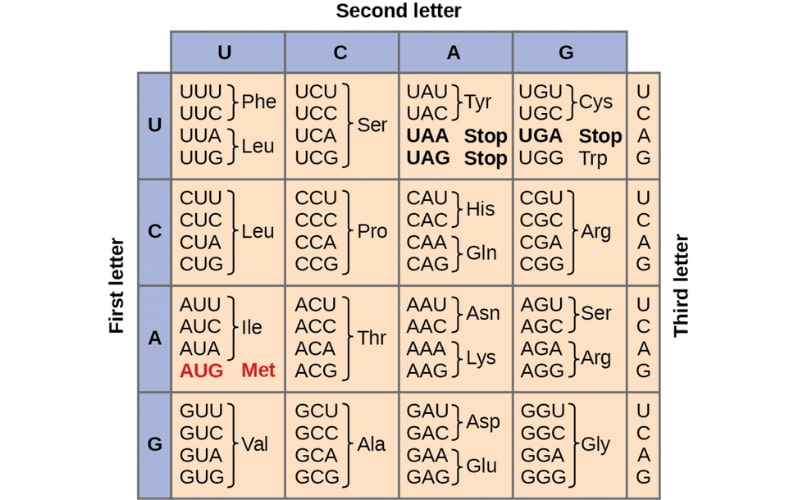
Quá trình đọc mã di truyền diễn ra một cách có trật tự và tuần tự theo từng nhóm ba nucleotide. Một điểm quan trọng là mỗi nucleotide chỉ thuộc về một codon duy nhất và không bao giờ được sử dụng cho codon tiếp theo, đảm bảo tính chính xác trong quá trình dịch mã.
Ví dụ cụ thể:
Quá trình đọc mã di truyền luôn tuân theo một hướng nhất định, từ đầu 5′ đến đầu 3′ của chuỗi nucleotide, trong đó mỗi bộ ba (codon) bao gồm một nucleotide ở đầu 5′, một nucleotide ở giữa, và một nucleotide ở đầu 3′. Việc duy trì hướng đọc này là vô cùng quan trọng vì nếu đọc ngược lại, trình tự nucleotide sẽ bị đảo lộn và dẫn đến việc tổng hợp các protein hoàn toàn khác.
Trong quá trình tổng hợp protein, codon AUG đóng vai trò là điểm khởi đầu. Có sự khác biệt giữa các nhóm sinh vật: ở sinh vật nhân chuẩn (eukaryote), chuỗi polypeptide bắt đầu bằng methionine, trong khi ở sinh vật nhân sơ (prokaryote), chuỗi này bắt đầu bằng N-formylmethionine.
Khác với các codon mã hóa axit amin, UAG, UAA và UGA là các codon kết thúc hoặc codon dừng. Chúng không được nhận diện bởi bất kỳ phân tử tRNA nào và cũng không mã hóa cho bất kỳ axit amin nào, mà chỉ đơn thuần đánh dấu điểm kết thúc của quá trình tổng hợp protein.
Một đặc điểm quan trọng của mã di truyền là tính liên tục – không có bất kỳ dấu phẩy hay khoảng trống nào giữa các codon. Các codon được sắp xếp liền kề nhau trong chuỗi DNA mà không có bất kỳ nucleotide nào chen vào giữa.
![]() Khuyến cáo y khoa: Các bài viết của Phòng khám Đa khoa Phương Nam chỉ có tính chất tham khảo, không thay thế cho việc chẩn đoán hoặc điều trị y khoa.
Khuyến cáo y khoa: Các bài viết của Phòng khám Đa khoa Phương Nam chỉ có tính chất tham khảo, không thay thế cho việc chẩn đoán hoặc điều trị y khoa.
Đa khoa Phương Nam I Thương hiệu thăm khám và chữa bệnh uy tín, chất lượng với đội ngũ và kiến thức y khoa hiện đại, cơ sở vật chất kỹ thuật tiên tiến. Vì cuộc sống là vô giá, chúng tôi đề cao triết lý “đón mừng cuộc sống”, đồng hành cùng với gia đình trong việc chăm sóc sức khỏe bệnh nhân
Hotline